陳穎志博士 香港理工大學 醫療科技及資訊學系
2019-11-20

![]() 根據術語間的醫學語義關係來計算醫學文件的相似度,是搜索算法於臨床決策應用上的關鍵技術。國際標準「醫學術語系統命名法 – 臨床術語」(Systematized Nomenclature of Medicine – Clinical Terms, SNOMED-CT),定義了這些臨床術語的醫學語義關係。如以下SNOMED-CT層次結構的樹狀結構圖所示,說明了從根到三個標準臨床術語之間的「是一個」(“is-a”)關係。這三個術語是「糖尿病,非胰島素依賴(C0011860)」,「支氣管炎 (C0006277)」 和「虹膜炎(C0022081)」。SNOMED-CT的術語分為多個層次,並以“is-a”鏈接關聯。根位於根本層次,連接到根的術語位於第一層(Level 1)。“is-a”鏈接根據語義關係將術語從一層映射到下一層。例如,從「代謝性疾病」(Level 3) 到「碳水化合物代謝失調」(Level 4) 存在“is-a”鏈接,因為「碳水化合物代謝失調」被歸入「代謝性疾病」,但是,相反方向的關係不應存在。同一層的術語之間亦不應存在任何“is-a” 鏈接,例如第四層(Level 4)的「特定身體結構或組織的炎症」和「碳水化合物代謝失調」。
根據術語間的醫學語義關係來計算醫學文件的相似度,是搜索算法於臨床決策應用上的關鍵技術。國際標準「醫學術語系統命名法 – 臨床術語」(Systematized Nomenclature of Medicine – Clinical Terms, SNOMED-CT),定義了這些臨床術語的醫學語義關係。如以下SNOMED-CT層次結構的樹狀結構圖所示,說明了從根到三個標準臨床術語之間的「是一個」(“is-a”)關係。這三個術語是「糖尿病,非胰島素依賴(C0011860)」,「支氣管炎 (C0006277)」 和「虹膜炎(C0022081)」。SNOMED-CT的術語分為多個層次,並以“is-a”鏈接關聯。根位於根本層次,連接到根的術語位於第一層(Level 1)。“is-a”鏈接根據語義關係將術語從一層映射到下一層。例如,從「代謝性疾病」(Level 3) 到「碳水化合物代謝失調」(Level 4) 存在“is-a”鏈接,因為「碳水化合物代謝失調」被歸入「代謝性疾病」,但是,相反方向的關係不應存在。同一層的術語之間亦不應存在任何“is-a” 鏈接,例如第四層(Level 4)的「特定身體結構或組織的炎症」和「碳水化合物代謝失調」。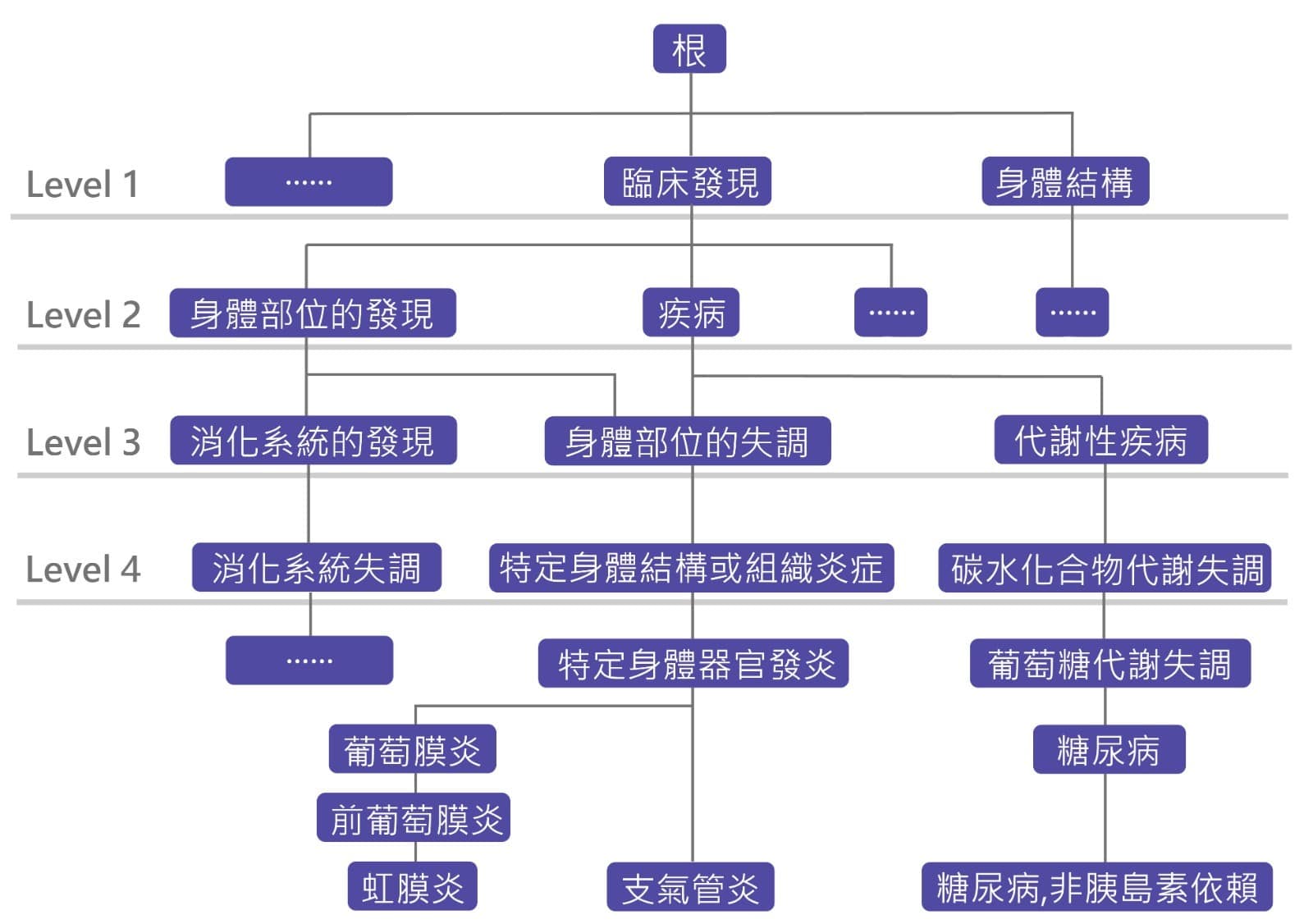 本文提出的醫學文件搜索算法是基於一個特徵向量模型。建立模型時,我們考慮SNOMED-CT層次結構中固定一層的一組術語,構成一個特徵空間。例如將第四層(Level4)定義為特徵空間,即特徵術語集,包括:「消化系統失調」,「特定身體結構或組織的炎症」 和「碳水化合物代謝失」等大概7000個標準術語。我們使用這些特徵術語將醫學文件中的每個術語數字化,從而形成一組特徵數值,稱為特徵向量。我們根據以下規則測量特徵數值:
本文提出的醫學文件搜索算法是基於一個特徵向量模型。建立模型時,我們考慮SNOMED-CT層次結構中固定一層的一組術語,構成一個特徵空間。例如將第四層(Level4)定義為特徵空間,即特徵術語集,包括:「消化系統失調」,「特定身體結構或組織的炎症」 和「碳水化合物代謝失」等大概7000個標準術語。我們使用這些特徵術語將醫學文件中的每個術語數字化,從而形成一組特徵數值,稱為特徵向量。我們根據以下規則測量特徵數值:
A.如果文件中術語被歸入特徵術語,即符合“is-a”鏈接的條件,算法就會計算出文件中術語和特徵術語之間路徑的“is-a”鏈接數量 n,即語義距離,並且得到特徵數值為 1/(n+1)。
B.如果文件中術語不被歸入特徵術語,即特徵數值為 0。
C.如果特徵術語與文件中術語相同,則特徵數值為 1。
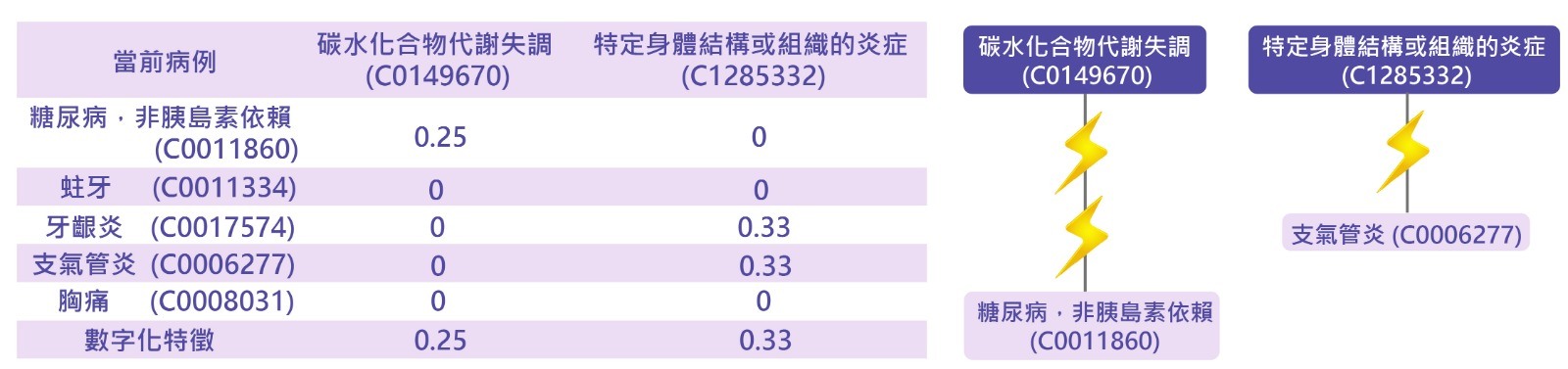
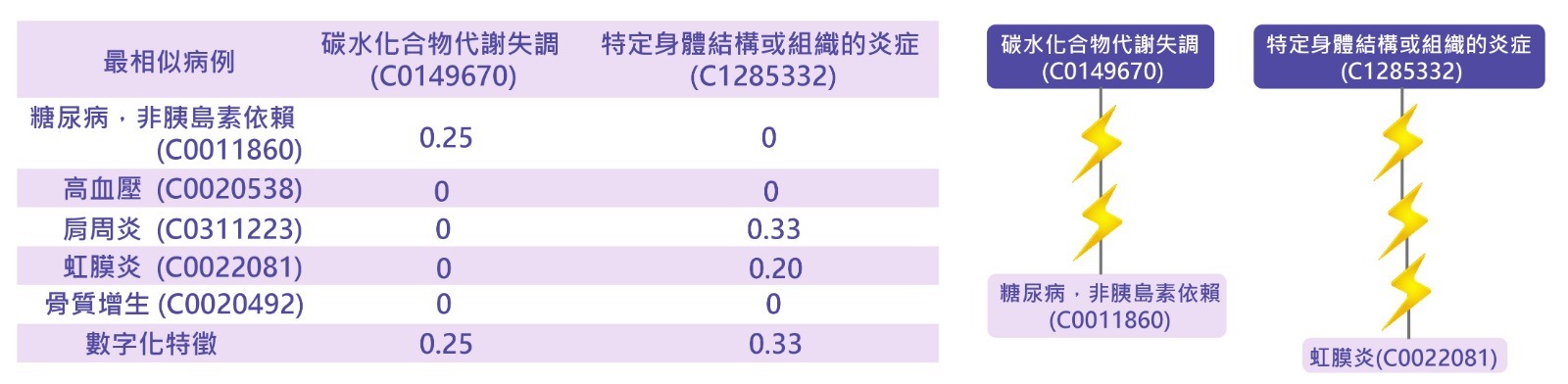
以術語「糖尿病,非胰島素依賴」為例,以 Level 4 術語為特徵空間。如下圖所示,「糖尿病,非胰島素依賴」與特徵術語「碳水化合物代謝失調」之間的語義距離為 3,因為「糖尿病,非胰島素依賴」與特徵術語「碳水化合物代謝失調」之間有三個“is-a”鏈接,得到特徵數值為 1/(3+1)=0.25。基於相同的原理,「支氣管炎」和「虹膜炎」都被歸入特徵術語「特定身體結構或組織的炎症」,它們的特徵數值分別為 1/(2+1)=0.33 和 1/(4+1)=0.2。當有多個文件中術語被歸入特徵術語時,算法會選擇最高特徵數值的作為最終的數字化特徵。這例子顯示當前病例和最相似病例的特徵向量同為 [0.25, 0.33],說明了這兩個病例相似的原因。![]()
 圖片來自以下期刊論文:
圖片來自以下期刊論文:
Chan LWC, Liu Y, Shyu CR, Benzie IFF. A SNOMED supported ontological vector model for subclinical disorder detection using EHR similarity. Engineering Applications of Artificial Intelligence 24:1398-1409, 2011.

香港理工大學醫療科技及資訊學系副教授
浙江大學核醫學與分子影像研究所客席教授
港澳抗癌協會常務理事
「健康及醫療人工智能」系列:
1.「健康及醫療人工智能」系列(1):人工智能於臨床和研究應用中的卓越特性
2.「健康及醫療人工智能」系列(2):人工智能基礎知識及醫學分析模型
4.「健康及醫療人工智能」系列(4):醫學文件搜索算法
5.「健康及醫療人工智能」系列(5):搜索引擎輔助製定放射治療計劃
6.「健康及醫療人工智能」系列(6): 搜索類似放射治療計劃的算法
7.「健康及醫療人工智能」系列(7): 基於功能性磁力共振數據的神經元連接模型
8.「健康及醫療人工智能」系列(8): 使用遺傳算法和GPU改善神經元連接模型
9.「健康及醫療人工智能」系列(9): 放射組學:醫學圖像的高通量測序
10.「健康及醫療人工智能」系列(10): 輔助醫學圖像分析的計算機視覺





